
熊猫OCR电脑版是一款十分强大的在线OCR文字图片转换工具,一款能够在电脑上轻松帮助用户实现最简单的转换方式,方便用户使用OCR。熊猫OCR电脑版官方版完全免费,不像网上那些某某厂商搞个收费,这款软件专为用户免费体验最简单的OCR识别方式,让用户可以在软件中轻松将图像中的文字识别成汉子。

熊猫OCR有很多识别引擎,不仅能识别,还能翻译以及朗读,程序加了ASP,体积虽然小了,但是运行起来有点小卡。
熊猫OCR电脑版特色
支持识别引擎:搜狗OCR/API+腾讯OCR/API+百度OCR/API+有道OCR/API+阿里OCR/API+京东OCR+华为OCR+网易OCR+讯飞OCR+金山OCR+灵云OCR+飞桨OCR+合合OCR+网校OCR+易道OCR+薪火OCR+必应OCR+SpaceOCR+YandexOCR
支持公式识别:微软公式+百度公式API+腾讯公式API+Mathpix公式API+网校公式+阿里公式
支持表格识别:有道表格+百度表格API+腾讯表格API+阿里表格/API
支持翻译引擎:搜狗翻译/API+腾讯翻译/API+百度翻译/API+有道翻译/API+谷歌翻译+词霸翻译+必应翻译+沪江翻译+奇虎翻译+海词翻译+小牛翻译+彩云翻译+福昕翻译+欧米翻译+微软翻译+阿里翻译+云译翻译+欧路翻译+灵云翻译+Deepl翻译API+PaPaGo翻译
支持朗读引擎:搜狗朗读x4+腾讯朗读x5+百度朗读x6+京东朗读x2+有道朗读x2+知声朗读x7+讯飞朗读+谷歌朗读+必应朗读
支持快捷键和屏幕边角触发截图识别功能,方便快速
支持截取识别固定区域,适合日语类游戏机翻或生肉字幕机翻
支持右侧小弹窗预览文本信息,快速查看识别/翻译内容
支持智能合并修正文本,让排版更合理,并提高翻译质量
支持设置最多十条固定截图规则,每条规则都能有自己的快捷键
支持监听图像和文本复制操作,快速识别图像文本或翻译复制文本
支持简单的窗口汉化功能,帮助翻译纯英文类软件界面文字
还有一些奇怪的没有列在程序界面上的功能,可以编辑程序目录下的CONFIG.INI配置文件试试
熊猫OCR电脑版使用技巧
将鼠标移到各功能组件或按钮上会显示简单的悬停提示帮助你理解程序操作。
配置文件内已添加各功能注释说明,如果想要实现某种功能但在程序界面上没找到相关设置,可以先翻一翻配置文件或许它已经在那里等着你(程序目录下CONFIG.ini即是配置文件)。
如果你有两块屏幕,请勾选“高级截图方式”以解决无法截取第二块屏的问题。
如果你是高分屏或修改了系统DPI缩放,可能出现截图不全或弹窗位置偏移的问题,此时你需要在此程序文件的属性中取消系统DPI设置。
程序界面上存在的设置多数是可以实时生效的不需要频繁点击保存按钮,比如设置语言、更换引擎此类。
有时手工更改了配置文件又不想重启软件可以试试右键点击界面左上角图标重载配置,不要点左键。
从演示版引擎临时更改为API版引擎可以右键点击引擎选择组合框。
鼠标党如果觉得按快捷键识别麻烦可以把鼠标移到屏幕左上角来触发识别,默认配置已启用,也可以编辑配置文件关闭或改为其他位置(配置项:边角触发截图)。
在截图时按住CTRL键可以临时取消识别,只截图并复制至剪贴板。
在截图时按住ALT键可以临时取消修正文本,当识别图像的文本中不包含任何标点符号时建议这样使用。
在文本区输入文本后按CTRL+回车键会直接翻译,不需要再用鼠标点翻译按钮。
在文本区输入文本后按ALT+回车键会直接朗读。
将图片直接拖入至程序界面上会自动开始识别。
在识别或是朗读进行中如果想中止任务可以双击界面右上方“线程”字样处,或按住空格键的同时点击托盘图标。
如果觉得文本区域过小,可以双击文本区使用大窗口浏览或简单编辑。
有些不太用的上的功能建议关闭以减少识别等待时间,比如朗读文本。
在启用了监听复制功能时临时不想执行识别或翻译可以在复制的同时按住空格键。
熊猫OCR电脑版API版接口申请
搜狗:
OCR:http://deepi.sogou.com (送100/200元体验金 | 可能需要先充点钱才能用)
翻译:http://deepi.sogou.com (送100/200元体验金)
腾讯:
OCR: (1000次/月免费 | 腾讯云接口)
OCR:https://ai.qq.com/v1/ (免费 | 腾讯AI旧版接口)
OCR:https://open.youtu.qq.com/ (500次/天免费 | 腾讯优图接口)
翻译:https://cloud.tencent.com (5百万字符/月免费 | 腾讯云接口)
翻译:https://ai.qq.com/v1/ (免费,不推荐,质量不如腾讯云 | 腾讯AI旧版接口)
公式: (1000次/月免费 | 腾讯云接口)
表格: (1000次/月免费 | 腾讯云接口)
百度:
OCR:https://cloud.baidu.com (50000次/天免费)
翻译:http://api.fanyi.baidu.com (免费)
公式:https://cloud.baidu.com (1000次免费)
表格:https://cloud.baidu.com (50次/天免费)
有道:
OCR:http://ai.youdao.com (送50元体验金)
翻译:http://ai.youdao.com (送50元体验金)
阿里:
OCR:https://market.aliyun.com/products/57124001/cmapi020020.html (通用版 | 500次/免费)
OCR:https://market.aliyun.com/products/57124001/cmapi028554.html (高精度 | 500次/免费)
OCR:https://market.aliyun.com/products/57124001/cmapi00040832.html (手写版 | 500次/免费)
OCR:https://market.aliyun.com/products/57124001/cmapi00040847.html (多语种 | 500次/免费)
表格:https://market.aliyun.com/products/57124001/cmapi024968.html (500次/免费)
讯飞:
OCR:https://www.xfyun.cn/services/textRecg (10万次/免费)
公式:https://www.xfyun.cn/services/formula-discern
网校(学而思/好未来):
OCR:https://ai.xueersi.com (10万次/天免费 | 10秒间隔/次 | 旧站)
OCR:https://ai.100tal.com (新站)
Deepl:
翻译:https://www.deepl.com/translator (付费且服务器延迟较高)
Mathpix:
公式:https://dashboard.mathpix.com (1000次/月免费)
SpaceOCR:
OCR:https://ocr.space/OCRAPI (25000次/月免费)
隐私安全:
程序:
程序本身不包含任何恶意代码,如有杀软误报请自行加入白名单(曾提交火绒人工检测为安全)
程序调用了一个51.la的统计,单纯用来统计使用人数,除此之外不会上传您的任何隐私数据
因功能需要,请使用管理员权限运行,程序会调用键鼠钩子,如“划词复制功能”需要鼠标钩子,为避免某些游戏屏蔽热键导致无法截图而使用了键盘钩子
程序的开发与发布均在ESET NOD32杀软保护的环境中完成,如果使用过程中,您系统中某种“安全”软件称「发现木马」,那么此种情形将考验您的判断力
引擎:
本程序不带离线引擎,所调用的识别/翻译/朗读等全部为在线引擎
理论上用户上传到各个引擎的数据都只是缓存数据,通常会在一定时间内清除
但服务器毕竟为各引擎所在公司控制和所有,我无法保证上传数据的绝对安全
所以如果您要处理的数据属于商业或机密数据,请换用其他自己可控的本地私有化产品
如因此发生的任何损失,本人表示概不负责
熊猫OCR电脑版wiki
公式识别
演示版:
启动程序,在识别引擎处选择公式识别 (在公式识别的情况下建议关闭自动翻译和自动朗读):
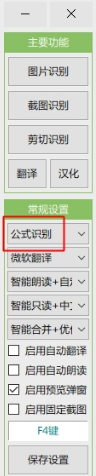
API版:
先注册百度云,获取ID和KEY
在配置文件中填入“百度OCRID”和“百度OCRSECRET”,并将“公式识别版本”设为1
启动程序,在识别引擎处选择公式识别 (在公式识别的情况下建议关闭自动翻译和自动朗读):如上图
文本排版或合并
目前PandaOCR支持以下几种不同的文本重新排版方式,如图:
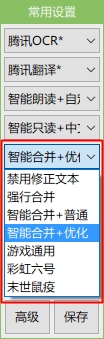
排版方式解释
禁用修正文本:什么也不做,OCR引擎接口返回什么就显示什么(通常包含原始换行,排版较乱)
强行合并:将多行文本强行合并为一行
智能合并+普通:先强行合并再以句号或感叹号等段落结尾符分割为多行文本
智能合并+优化:判断每行文本最后字符是否为句号或感叹号等结尾符,如果是则换行,否则与下一行合并(对段落文章效果佳)
游戏通用:对游戏中的队友聊天内容进行优化,比如忽略系统消息等字眼
彩虹六号:在游戏通用的基础上对彩虹六号.围攻游戏进行优化
末世鼠疫:在游戏通用的基础上对末世鼠疫游戏进行优化
为什么要重新排版?
因为OCR通常无法区分图片中上行两行的文本是否属于同一行,图像中有多少行就返回多少行
通俗讲就是OCR无法识别当前内容是文本自身带换行还是因文本框或屏幕宽度小于文本长度时的自动换行
如果还是无法理解那请看图:
图中文字虽然看上去是三行,但其实是一整行,只因编辑框的宽度限制,它被自动换行以显示完整内容
而在通用OCR眼里这就是三行文本,所以在OCR识别后返回的也是三行文本
但我们知道这其实是一行,所以为了让排版更合理或便于阅读,需要在识别后对文本进行重新排版
我该选择哪种排版方式?
通常这取决于你用来识别的是怎样的文本
如果是完整且包含段落的文章,学术论文,建议使用 智能合并+优化
如果是列表式的文本(指多行文本且文本行末尾缺少句号或感叹号用以结尾),建议不要重新排版,使用 禁用修正文本
为了避免在识别不同样式的文本中来回切换排版方式,其实可以使用 智能合并+优化,并在临时不需要重新排版的时候,在截图识别时按住ALT键即可
小声逼逼:
其实OCR返回的数据中通常也包含每行或每个文字的位置信息,理论上可以基于位置信息实现另一种排版方式
但由于不同OCR引擎返回的位置数据都不一致,如果要增加基于位置排版还需要先将各引擎的位置数据统一化
这对已经内置20多个引擎接口的PandaOCR来说也算是项大工程,由于目前的排版方式已经基本够用,所以基于位置排版的方式暂不研究


精品软件
easyconnect官方下载 v6.3.0.1 电脑版
![easyconnect官方下载 v6.3.0.1 电脑版]()
15.6M ︱ 简体中文
下载Worktile电脑版 v7.2.0 个人版
![Worktile电脑版 v7.2.0 个人版]()
41M ︱ 简体中文
下载office 365安装包下载 免费完整版
![office 365安装包下载 免费完整版]()
1.88G ︱ 简体中文
下载Microsoft Project 2010 电脑版下载
![Microsoft Project 2010 电脑版下载]()
395M ︱ 简体中文
下载microsoft office outlook官方下载
![microsoft office outlook官方下载]()
4.5M ︱ 简体中文
下载印象笔记软件下载 v6.20.2.1568 官方版
![印象笔记软件下载 v6.20.2.1568 官方版]()
136M ︱ 简体中文
下载Teambition电脑版 v1.13 官方版
![Teambition电脑版 v1.13 官方版]()
44M ︱ 简体中文
下载闪电pdf合并软件下载 v6.6.1.0 电脑免费版
![闪电pdf合并软件下载 v6.6.1.0 电脑免费版]()
43.7M ︱ 简体中文
下载




























- WinRAR Final(正版KEY/无视文件锁定)v2 烈火汉化特别版v3.93
- FlashFXP Beta1(3.7.9 Build 1348)烈火汉化绿色特别版v3.8
- ZoneAlarm Pro for 2000/XP(五星级个人防火墙))汉化特别版V7.0.438.000
- Autorun病毒防御者 简体绿色免费版v2.37.350
- 小说下载阅读器(知道小说名称即可下载阅读) 简体绿色版v11.6
- KoolMoves(制作动画GIF制作文字特效增加帧动作等) 汉化绿色增强特别版v8.10
- BetterJPEG(裁剪缩放JPG压缩图片)汉化绿色特别版v2.0.0.9
- 谷歌拼音输入法 绿色版(互联网上流行词汇一网打尽) 中文免费版v2.7.21.114
- AusLogics Registry Defrag(分析整理注册表碎片)汉化绿色版V4.0.4.47
- NetInfo(功能完善的网络工具箱) Build 715汉化绿色特别版V6.2
- 搜狗拼音智慧版 去广告优化版v3.0
- 波尔远程控制(远程监控管理) 简体绿色版v9.1
- Smart Defrag Portable 多国语言绿色便携版v6.4.0.256
- Wise Registry Cleaner Pro中文绿色版v10.2.6
- 五星注册表清理与系统优化(WinASO Registry Optimizer )汉化绿色特别版v4.7.5
- 音频编辑(Goldwave)汉化绿色版v6.32
用户评论
最新评论
- 置顶 辽宁盘锦联通 网友 月亮警察
拿走了
- 置顶 广东湛江电信 网友 鹤隐
非常喜欢这款软件。
- 置顶 河南商丘电信 网友 岁月沉淀
很好的软件,谢谢,辛苦了!
- 置顶 山东东营电信 网友 可爱到不行
来看看好不好用
- 置顶 青海西宁电信 网友 寒尘
正好需要 ,感谢
最新专题
更多>最新更新
更多>热门标签
软件排行榜
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10