
Alluxio架构是一款可以用于虚拟式数据分布储存应用的实用软件,它是世界上第一款采用内存为中心建立储存的软件。应用只需要连接Alluxio,即可快速访问存储在底层任意存储系统中的数据,大大提高了运行效率,是我们的办公的好帮手!
随着电脑技术的发展,日常工作中所需要处理的信息流也越来越大,当信息过多的时候就会导致读取数据变慢的问题,非常影响体验,使用Alluxio虚拟数据存储系统可以做到将数据分布在多级缓存中,从而起到了提高读取数据速度的效果。
【Alluxio架构软件背景】
Alluxio(之前名为Tachyon)是世界上第一个以内存为中心的虚拟的分布式存储系统。它统一了数据访问的方式,为上层计算框架和底层存储系统构建了桥梁。 应用只需要连接Alluxio即可访问存储在底层任意存储系统中的数据。此外,Alluxio的以内存为中心的架构使得数据的访问速度能比现有方案快几个数量级。
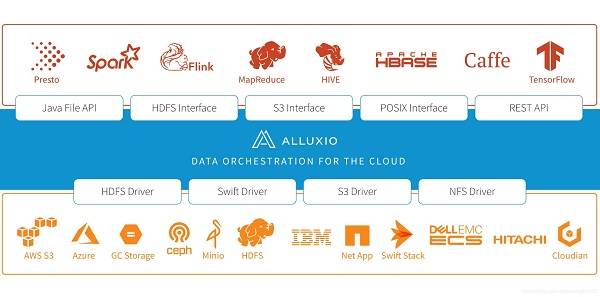
【Alluxio架构软件特点】
灵活的文件API:
Alluxio的本地API类似于java.io.File类,提供了 InputStream和OutputStream的接口和对内存映射I/O的高效支持。我们推荐使用这套API以获得Alluxio的完整功能以及最佳性能。
兼容Hadoop HDFS的文件系统接口:
基于这套接口Hadoop MapReduce和Spark可以使用Alluxio代替HDFS。
可插拔的底层存储:
Alluxio支持将内存数据持久化到底层存储系统。Alluxio提供了通用接口以简化对接不同的底层存储系统。目前Alluxio支持Microsoft Azure Blob Store,Amazon S3,Google Cloud Storage,OpenStack Swift,GlusterFS, HDFS,MaprFS,Ceph,NFS,Alibaba OSS,Minio以及单节点本地文件系统,后续也会支持更多其他存储系统。
Alluxio层级存储:
Alluxio可以管理内存和本地存储如SSD和HDD,以加速数据访问。如果需要更细粒度的控制,分层存储功能可以用于自动化管理不同层之间的数据,确保热数据在更快的存储层上。自定义策略可以方便地应用到Alluxio,而且pin(钉住)的概念允许用户显式地控制数据的存放位置。
统一命名空间:
Alluxio可以通过挂载功能实现不同存储系统之间的高效数据管理。并且,透明命名机制在持久化存储对象到底层存储系统时可以保留存储对象的文件名和目录层次结构。
Web UI: 用户可以通过Web UI浏览文件系统。在调试模式下,管理员还可以查看每一个文件的详细信息,包括存放位置,检查点路径等。
命令行:
用户也可以通过./bin/alluxio fs与Alluxio交互,例如:实现将数据从文件系统拷入拷出。
【Alluxio架构使用方法】
1. 前言
随着移动互联网的发展,越来越多的业务数据和日志数据需要用户处理。从而,用数据去驱动和迭代业务发展。数据处理主要包括:计算和查询。计算主要为离线计算、实时流计算、图计算、迭代计算等;查询主要包括Ahdoc、OLAP、OLTP、KV、索引等。然而,在数据业务中,我们时常听到数据需求方和数据开发方对性能慢的不满,所以,如何高效响应海量且迫切的数据需求,是大数据平台需要面对的一个关键问题,本文将介绍如何基于Alluxio建设分布式多级缓存系统对数据进行计算加速和查询加速。
2. 离线数据计算查询加速问题
对于加速组件,结合生态兼容性和系统成熟性的基础上,我们选择Alluxio,我们知道,Alluxio是通过UFS思想访问底层持久化的分布式数据。通常,我们的数据主要存放在公司私有HDFS和MySQL上。那么,如何通过UFS思想访问到私有HDFS数据进行加速是我们面对的主要问题。私有HDFS由于历史原因,其基于的HDFS版本较低,加上公司对HDFS进行了部分改造,使得开源的计算和查询组件访问公司内部的离线数据较为困难。因此,如何打通Alluxio访问私有HDFS成为了系统的关键,后面的章节中,我们会做相关介绍。
3. 基于Alluxio的解决方案
整体上,我们当前的多级缓存系统由私有HDFS(PB级别) + MEM(400G) + SSD(64T)共3层组成。 示意如下:
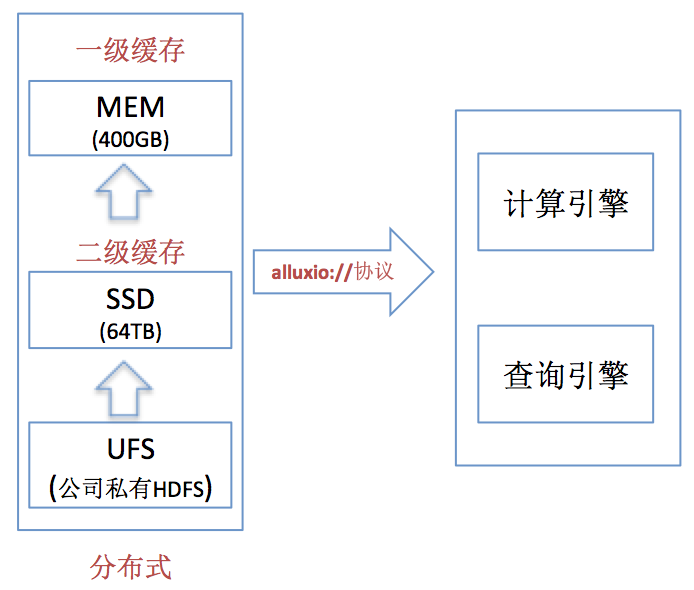
系统会根据类似LRU思想对热点数据进行缓存。我们主要存放热点部门核心数据。由于资源申请原因,我们的Alluxio在南方,UFS在北方,所以后面的测试数据均为跨地域性能数据,提供基于Spark、Hive、 Presto、YARN、API等方式访问数据。
对于多级分布式缓存系统,我们实现的整体示意图如下:
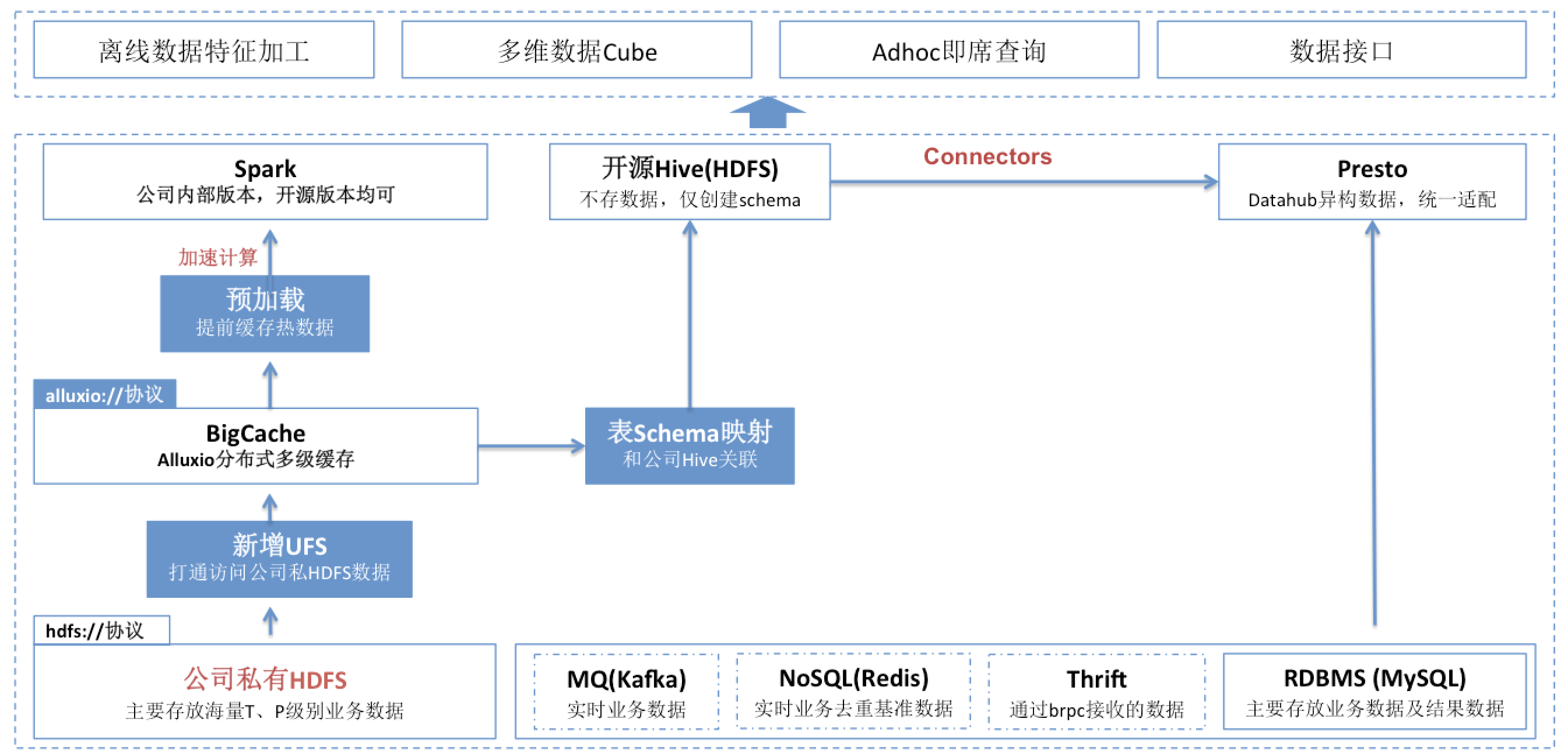
从上述方案中,我们可以看出,如果通过path路径方式访问私有HDFS数据,直接使用alluxio://协议路径即可;但是,如果要开源的Hive或者开源组件(基于Hive桥接)以数据表方式访问公司内部的私有HDFS数据,需要进行“表schema映射”,思路如下图:
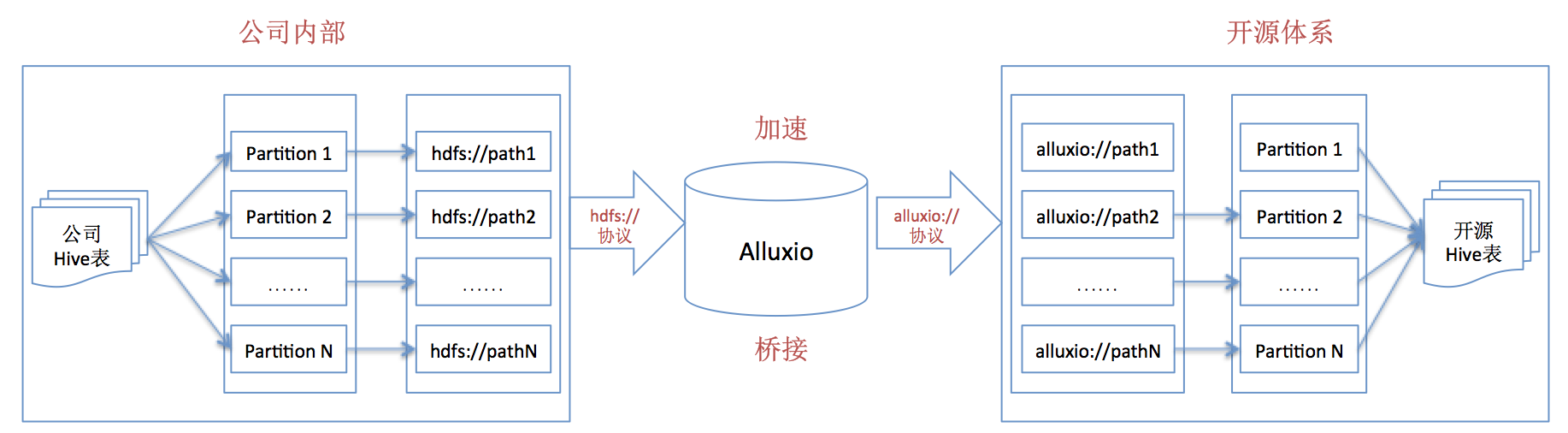
基于上述方案,可以大致抽象出使用Alluxio的几个一般性步骤,如下:
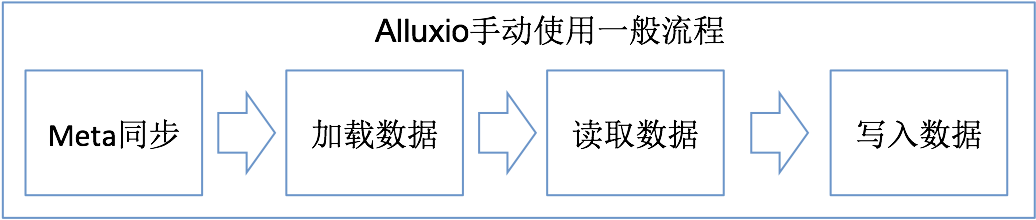
下面,我们会一一对每个步骤进行相关说明及案例数据分析。
3.1 Alluxio Meta数据同步(load和sync)
由于UFS随时可能会有变动,导致Alluxio Meta和UFS的Meta不一致,那么,如何在Alluxio的master中同步UFS文件的Meta十分重要,由于Alluxio Meta的load和sync性能成本较高(对于load和sync区别,本文不赘述),官方不推荐过度频繁load和sync Alluxio的Meta数据。
3.2 Alluxio加载数据
3.2.1 数据加载方案
有了缓存系统,那么,我们需要提前常用数据预加载到缓存系统中,如此,当用户使用时候,直接从缓存中读取,加快读取速度。数据预加载的方式有如下图的3种方式:

3.3 Alluxio数据的读取
3.3.1 数据本地化
本地化数据,相信大家都比较清楚,使用本地数据可以有效地提到数据读取效率,具体可以将每个worker节点的alluxio.worker.hostname设置为对应的$HOSTNAME,熟悉Spark的同学知道,这个设置类似Spark中的SPARK_LOCAL_HOSTNAME设置。
3.3.2 读取性能数据1(私有HDFS-\u0026gt;Alluxio-\u0026gt;Hive/Presto)
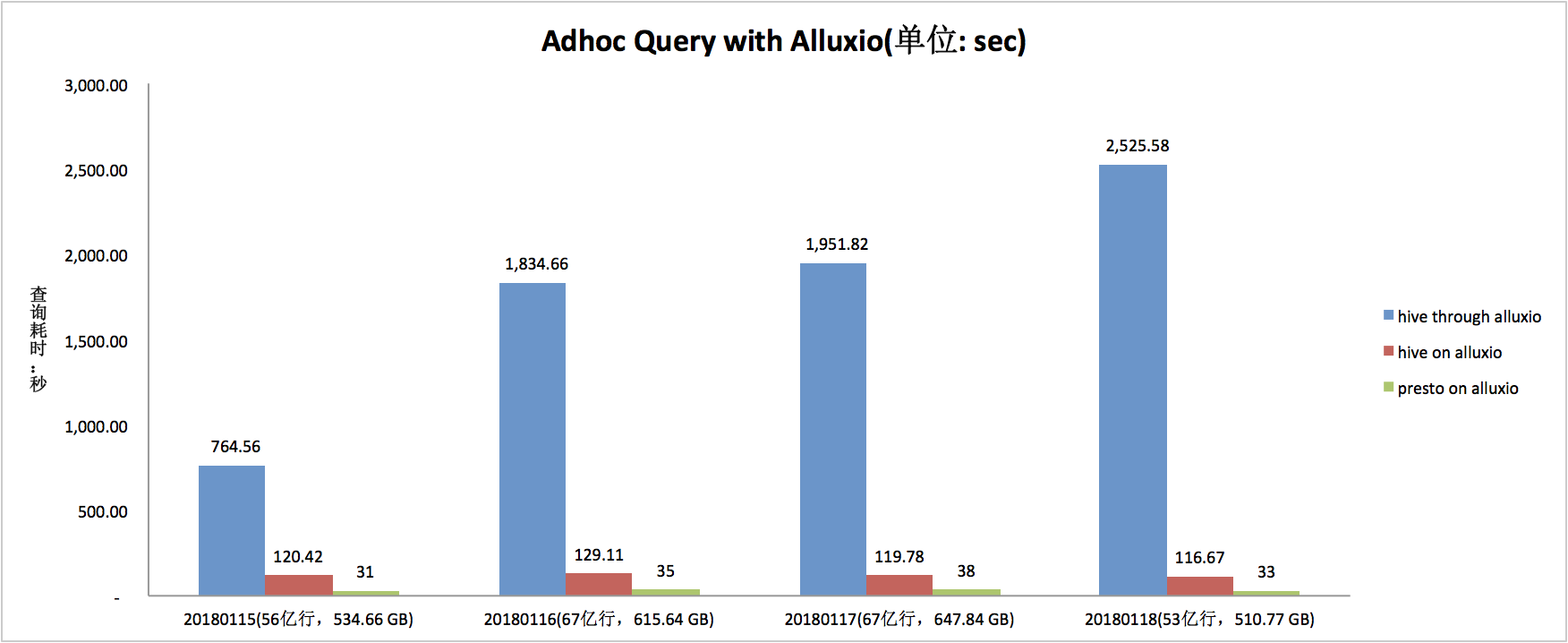
上图中,介词through和on的区别是,前者为首次从UFS上加载数据(即直接从私有HDFS上读取数据),后者为直接从Alluxio缓存中读取数据。
【Alluxio架构应用场景】
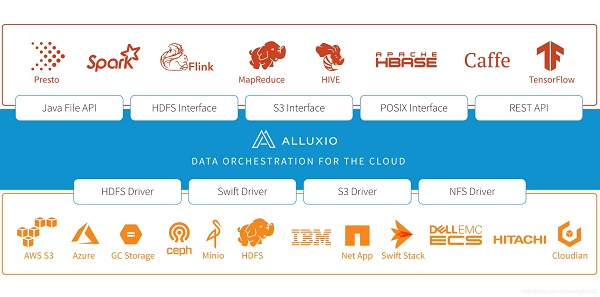
与其他诸如HDFS、HBase、Spark等大数据相关框架一致,Alluxio也是一个主从结构的系统。它的主节点为Master,负责管理全局的文件系统元数据,比如文件系统树等,而从节点为Worker,负责管理本节点数据存储服务。另外,Alluxio还有一个组件为Client,为用户提供统一的文件存取服务接口。
当应用程序需要访问Alluxio时,通过客户端先与主节点Master通讯,或许对应文件的元数据,然后再和对应Worker节点通讯,进行实际的文件存取操作。所有的Worker会周期性地发送心跳给Master,维护文件系统元数据信息和确保自己被Master感知扔在集群中正常提供服务,而Master不会主动发起与其他组件的通信,它只是以回复请求的方式与其他组件进行通信。这与HDFS、HBase等分布式系统设计模式是一致的。
精品软件
守望者加速器免费下载 v2020.01.27 官方版
![守望者加速器免费下载 v2020.01.27 官方版]()
17.2M ︱ 简体中文
下载xinput1_3.dll官方下载 v9.18.944.
![xinput1_3.dll官方下载 v9.18.944.]()
42KB ︱ 简体中文
下载media creation tool官方下载 v190
![media creation tool官方下载 v190]()
7.8M ︱ 简体中文
下载360急救箱官方下载 v 5.1.0.1223 电脑版
![360急救箱官方下载 v 5.1.0.1223 电脑版]()
37.2M ︱ 简体中文
下载nvidia控制面板下载 win10 官方版
![nvidia控制面板下载 win10 官方版]()
16.4M ︱ 简体中文
下载directx修复工具下载 win10 官方版
![directx修复工具下载 win10 官方版]()
99.6M ︱ 简体中文
下载驱动人生万能网卡版下载 v7.2.3.10 绿色版
![驱动人生万能网卡版下载 v7.2.3.10 绿色版]()
213M ︱ 简体中文
下载鲁大师绿色版下载 v5.1020.1120.114 官方
![鲁大师绿色版下载 v5.1020.1120.114 官方]()
58.3M ︱ 简体中文
下载




























- [未上架]Windows XP SP2 MSDN原版光盘(592M)v1.0
- 火绒剑单文件版绿色下载 独立版v5.0.47
- QVE视频压缩软件电脑版 免费版v1.0.25
- padlock密码管理软件最新下载 官方版v3.1.1
- 文件夹加密精灵(文件夹加密的利器) 绿色特别版v4.20
- 反间谍木马(Zemana AntiLogger )中文注册版v1.9.3.602
- AusLogics Registry Defrag(分析整理注册表碎片)汉化绿色版V4.0.4.47
- NetInfo(功能完善的网络工具箱) Build 715汉化绿色特别版V6.2
- 五星注册表清理与系统优化(WinASO Registry Optimizer )汉化绿色特别版v4.7.5
- OO Defrag Server Edition(适用于服务器版的磁盘整理)10.0.1634汉化特别版v10.0.1634
- 星云游戏修改器(修改游戏中所有的数值) 简体绿色版v2.42
- Photoshop CC 32位中文便携版 v15.2.2.310
- [未上架]RM.RMV格式转换(Allok RM RMVB to AVI MPEG DVD Converter)2.2.0807汉化绿色特别版v1.0
- CPU超频工具(CrystalCPUID )汉化绿色版v4.15.2.451
- 微软恶意软件删除工具(x86)官方中文版v5.76
- FreePic2Pdf 中文绿色版v4.06
用户评论
最新评论
- 置顶 云南曲靖电信 网友 笙念
此软件必火,先占位支持了,谢谢分享
- 置顶 江苏泰州联通 网友 眉儿皱
可以可以,牛
- 置顶 河南信阳电信 网友 半城烟沙自寂寥
太牛了!!
- 置顶 广西崇左联通 网友 只剩余生
很需要这种软件,谢谢分享。
- 置顶 新疆吐鲁番电信 网友 落琼
不错不错!
最新专题
更多>最新更新
更多>热门标签
软件排行榜
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10